Today we continue our post about microservices
Serverless
With the release of the AWS serverless services and the rising popularity of micro services and serverless architecture accompanied with the increased demand on the use of NoSQL databases, there have been a lot of questions from developers community about how these two technologies relate to each other and when you should use one or the other or both.
Serverless is the native architecture of the cloud that enables you to shift more of your operational responsibilities to the cloud. Serverless architectures are application designs that incorporate third-party “Backend as a Service” (BaaS) services, and/or that include custom code run in managed, ephemeral containers on a “Functions as a Service” (FaaS) platform. Serverless allows you to build and run applications and services without thinking about servers. It other words, it allows you to build and run applications without provisioning, scaling, and managing any servers. Therefore, it eliminates infrastructure management tasks such as server or cluster provisioning, patching, operating system maintenance, and capacity provisioning. There are its own pros and cons in tandem with certain system architecture requirements which will be presented below.
One of the greatest advantages of using serverless is a deployment which is achieved by no administration of infrastructure needed. That is to say, that developers and operations do not need to worry about any Dockerfiles or Kubernetes configurations,but think about right server configuration, etc.
Similarly with the simplified deployments, the process of functions modifications becomes drastically easier. Furthermore, this benefit is partially connected with the first one, which demonstrates how quickly these changes can be deployed. Another benefit is that by using serverless you can make absolutely scalable platform because it is automatically provided by the cloud provider.
There are a variety of other advantages among which:
- It has in built support for versioning
- Simple integration with other cloud provider service
- Out of the box support for event triggers which makes serverless functions to be a great for pipelines and sequenced workflows.
Apart from the technological benefits, there are benefits for the business which are related with how serverless is paid. Because it is a FaaS (Function as a Service) platform you pay per function execution and resources it consumes which makes serverless dramatically cheaper than containers or monolith applications deployed to instances in the cloud or on-premises instances. This benefit makes serverless technologies to be the prevalent choice for startups that are short on cash. However, as any other technology serverless has its own disadvantages. Where one of the most obvious one is that serverless is a “black box” technology, which makes functions to be executed on the environment without giving you an understanding what’s going on.
Another drawback, and probably the most severe one, is the complexity of the serverless architecture which can exponentially grow with linear application grow. In other words, without the proper tools to be configured the process of troubleshooting can take hours if not days. For instance, AWS provides you with services which can help with:
- logging (CloudWatch) your Lambdas and API Gateway,
- constructing service maps (AWS X-Ray) which can significantly reduces time on tracing the problem,
- preparing flowcharts of your microservices execution chains (AWS Step Functions),
- simplifying the entire deployment process (AWS SAM, CodeDeploy, CodeBuild, CodePipeline),
- hoocking different deployment stages by embedded interaction between AWS services.
Tools will be described in a little bit more detailed further in the document.
Next disadvantage is a consequence of some benefits declared above. Due to the high integrity of cloud provider services which can be utilized by hundreds if not thousands of functions and the fact that the entire serverless architecture depends on a third party vendor, then it becomes almost impossible to easily change a cloud provider even if it is needed. The key word here is ‘almost’ because these risks can be mitigated by choosing the right architecture. In order to reduce the risk of being locked by vendor the entire architecture should not have any parts wirth strong coupling between business logic and the AWS SDK specific logic. Technically Lambda is a just function and S3 is a simple storage, the same like DynamoDB is just a database. Therefore, considering this, you can secure yourself by using a couple of abstraction layers for processing and outputting data. Basically, none of your services should have a direct communication with Amazon service which will certainly make code less straight forward, but will save you from enormous migration costs and will allow reuse your business logic as much as possible if you decide to move to a different serverless provider one day. This approach also makes you code more readable and maintainable. Moreover it is better for testing. To achieve it all microservices should be designed using DI technique. A good example can be found here.
The last but not least, it is worth to expose some of the system architecture requirements. Most of the requirements are related with serverless platform restrictions such as 900 seconds as the up limit of function execution or the maximum amount of memory which can be allocated.
Lastly, the stack of services in the cloud provider can be selected based on the company needs or pre-existing aspects such as cloud services which are already in use. Serverless computing can be backed by the variety of cloud provider services such as Amazon AWS Lambda, Microsoft Azure functions, Google GCF or Google Cloud Functions. However, this document will focus on description of the serverless and container related services provided by the AWS and how architecture can be established more efficiently. Moreover, this document will elucidate how auto deployments and orchestration can be configured and how distributed serverless applications can be built and debugged using visual workflows.
Tools and services
Prior to talk over serverless best practices, file structure, name conventions, what data storage should be used, what services we need, we have to understand what our stack will be, what core AWS services will be utilized and will become the main pillars of the architecture we are building. A central part of every app is a code, which in the case of serverless is a compute service which is called AWS Lambda. It can execute code in response to events in a massively parallel way. Moreover, it can respond to HTTP requests using the AWS API Gateway, events raised by other AWS services, or it can be invoked directly using an SDK. But Lambdas on their own cannot make the system. Furthermore, as it can be concluded from the mentioned above information without mitigating the complexity, all the benefits of using microservices or even serverless will be outweighed by their disadvantages. It can be achieved by selecting the proper tools and by understanding of how the system should work. Needless to say, that there are a variety of different services which can be utilized in order to make the fully working serverless application, however like everywhere else certain things should be done first and certain things can make the architecture more convoluted or even non efficient. Thereby, further in the document most of the core AWS serverless services and other important for the development stuff will be highlighted.
Guidelines and best practices
Because now we have an understanding of what problems we can face with and familiar with the stack of technologies we will utilize, we have to formalize the steps of how the project will be built and what are the best practices, etc.
Based on the knowledge that one of the main pitfalls of using microservices is the complexity, our first step should be how it can be mitigated in order to prevent the nightmare of both maintainability and problems identification. Therefore, before doing any microservices work we should set up the infrastructure properly.
Deployment automation has to go first
To begin with SAM has to be configured to automate the deployment of all serverless services which we are going to build. Without this step any further work on building serverless modules should be delayed because the complexity can become significantly high pretty quickly which will make the life of operational engineers, developers and deployment manager drastically harder. After you develop and test your serverless application locally, you can deploy your application by using the SAM package and sam deploy commands. The SAM package command zips your code artifacts, uploads them to Amazon S3, and produces a packaged AWS SAM template file that’s ready to be used. The sam deploy command uses this file to deploy your application. The following steps should be done in order to package and then deploy your serverless code:
- Install Python
- Download the latest version of python https://www.python.org/downloads
- Install it. If it was successfully installed, then by typing python in your cmd you should see this message.

- If you do not see it, please do the following steps:
- Press
Win+R - Type
sysdm.cpl - Go to Advanced tab
- Open Environment Variables
- Select Path
- Add a new path entry for Python (on my laptop it is this –
C:\Users\admin\AppData\Local\Programs\Python\Python37-32) - Add one more entry for Python Scripts (on my laptop it is this –
C:\Users\admin\AppData\Local\Programs\Python\Python37-32\Scripts)
- Press
- Install pip if it was not installed with the python (latest version of python normally has pip installed with it) by executing this command python get-pip.py. In order to do this you have to download pip in any of your folders (can be done from here https://bootstrap.pypa.io/get-pip.py), open cmd from the folder where you save your downloaded
get-pip.pyand executepython get-pip.py.
- Install aws sam cli by executing this command
pip install aws-sam-cli - Create an S3 bucket:
aws s3 mb s3://mysammainbucket --region ap-southeast-2 #use the bucket name and region name of your choice - it must match the default region that you are working in. - Package your deployment
sam package --template-file lambda.yml --output-template-file sam-template.yml --s3-bucket admin-mainsambucket #use the bucket name you used in the previous stepAfter the package is successfully generated you should see successful message and the resultsam-template.ymlwill look like this:AWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Resources: TestFunction: Type: AWS::Serverless::Function Properties: Handler: index.handler Runtime: nodejs8.10 CodeUri: s3://admin-sam/a6382f0f9babe46af8f48528a30d6602 - Deploy your package
sam deploy --template-file sam-template.yml --stack-name sam-teststack --region ap-southeast-2 --capabilities CAPABILITY_IAM
After the package is successfully deployed you should see this message

In the case when application contains one or more nested applications, you must include the CAPABILITY_AUTO_EXPAND capability in the sam deploy command during deployment.
AWS SAM can be used with a number of other AWS services to automate the deployment process of your serverless application:
- CodeBuild: You use CodeBuild to build, locally test, and package your serverless application.
- CodeDeploy: You use CodeDeploy to gradually deploy updates to your serverless applications.
- CodePipeline: You use CodePipeline to model, visualize, and automate the steps that are required to release your serverless application.
Think about flowcharts describing your architecture
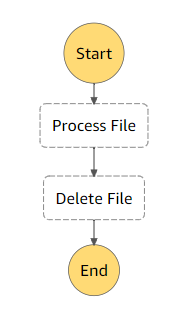
In this paragraph I would like to discuss aws service without which you relationship with FaaS systems can easily develop into the nightmare due to the fact that your workflow simply does not fit into the model of small code fragments executed by events. In other words this means either your project requires a more complex organization, or you need the program to run continuously – or for some significant period of time, which is essentially the same thing. Projects with a complex organization has to be covered by AWS Step Functions. It allows the developer by using a graphical interface to create flowcharts that describe lengthy processes. Any Step Function is defined the steps of your workflow in the JSON-based Amazon States Language which you basically need to learn. There are various ways step functions can be used. You can have the most trivial form of it by having a sequential step which can be described this way:
{
"Comment": "Sequential steps example",
"StartAt": "Process File",
"States": {
"Process File": {
"Type": "Task",
"Resource": “arn:aws:lambda:us-east-1:123456789012:function:ProcessFile",
"Next": "Delete File"
},
"Delete File": {
"Type" : "Task",
"Resource": "arn:aws:lambda:us-east-1:123456789012:function:DeleteFile",
"End": true
}
}
}
It will visually be represented by this workflow
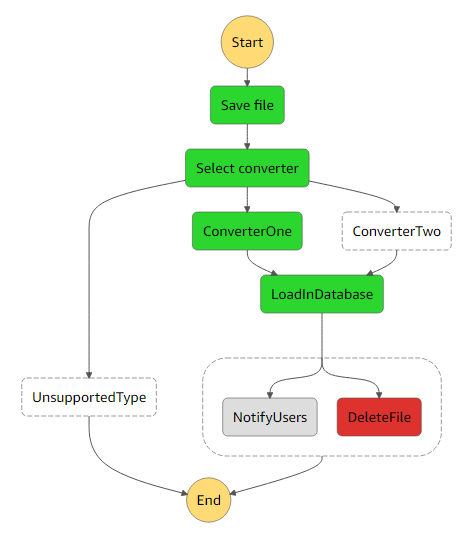
Besides the sequential path you can declare a more complex flowchart with the branching steps and even parallel steps. There is an example of how it can look like below:
{
"Comment": "An example of the Amazon States Language using a choice state.",
"StartAt": "Save file",
"States": {
"Save file": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:123456789012:function:ProcessFile",
"Next": "Select converter"
},
"Select converter": {
"Type" : "Choice",
"Choices": [
{
"Variable": "$.type",
"NumericEquals": 1,
"Next": "ConverterOne"
},
{
"Variable": "$.type",
"NumericEquals": 2,
"Next": "ConverterTwo"
}
],
"Default": "UnsupportedType"
},
"ConverterOne": {
"Type" : "Task",
"Resource": "arn:aws:lambda:us-east-1:123456789012:function:ConverterOne",
"Next": "LoadInDatabase"
},
"ConverterTwo": {
"Type" : "Task",
"Resource": "arn:aws:lambda:us-east-1:123456789012:function:ConverterTwo",
"Next": "LoadInDatabase"
},
"UnsupportedType": {
"Type": "Fail",
"Error": "DefaultStateError",
"Cause": "Type is not supported"
},
"LoadInDatabase": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:123456789012:function:LoadInDatabase",
"End": true
}
}
}
It will visually be represented by this workflow
After your design is finished you can create resources for your work using cloudformation template which will be automatically generated based on your steps definition. When all resources are created you can start the execution and have a real time visualization of your defined flow. The visualization will looks like the image on the right and it demonstrates you how the execution is going. All the steps are logged and can be reviewed at the bottom of the execution window, so developers can easily detect the problem and find a solution. In this particular example, toy can see that there is an error occuring during execution.